
Explainable AI (XAI)
Making AI technology more trustworthy and transparent depends on our ability to explain why an AI system took a certain decision. The goal of XAI is to allow humans to ask and receive explanations from AI systems that are comprehensible by humans. To reach this goal TrustAI focus on two core concepts: genetic programs and human causal explanations. Genetic programs are AI algorithms that learn from data but output symbolic expressions that can be inspected by humans. Human explanations have been reported to highlight specific cause-effect relations and take into account the knowledge of the person receiving the explanation. TrustAI is combining these two fields together with feedback from human evaluators to produce human interpretable explanations of automated decision systems. In particular, TrustAI technology will be applied to provide explanations for AI solutions in the fields of medical oncology, energy forecast, and retail logistics.
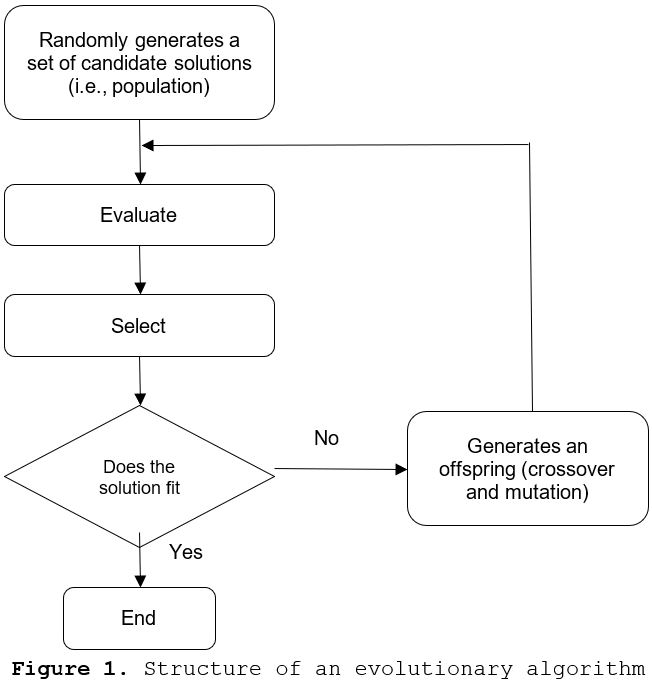
Evolutionary Algorithms
Machine learning (ML) methods commonly differ in the way they learn from their environment. Evolutionary computation (EC), for instance, models the world as a biological system by which genetic variation and sexual reproduction lead to long-term learning. In other words, in evolutionary computing, learning is a byproduct of a long natural selection process as stated by the Darwinian evolution theory. It means that in evolutionary computation, solutions are not built from the first principles, but evolved based on a quality measure, aka fitness, which indicates how well each candidate solution performs according to the chosen goal. Precisely, evolutionary algorithms work by choosing a search space where to look for solutions and setting up their goal by designing an ad-hoc fitness function. Thus, after randomly choosing initial candidate solutions (aka population of individuals), the algorithm (Figure 1) updates the population in successive iterations (aka generations). One generation first selects the most promising individuals (aka parents) in the current population according to their fitnesses, applies stochastic variation operators (by both combining different individuals through crossover operators and randomly modifying the individuals with mutation operators). The algorithm then evaluates the resulting new individuals before incorporating them into the population, applying another selection step amongst newborn and parents. The algorithm stops when it obtains sufficiently performing solutions or when the computing budget is over. There exist many variants of Evolutionary Algorithm, characterized by the search space they explore and the corresponding variation operators. Among the most popular are Genetic Algorithm (bitstrings) and Evolution Strategies (continuous parameters), and Genetic Programming (GP), that explores functional spaces.
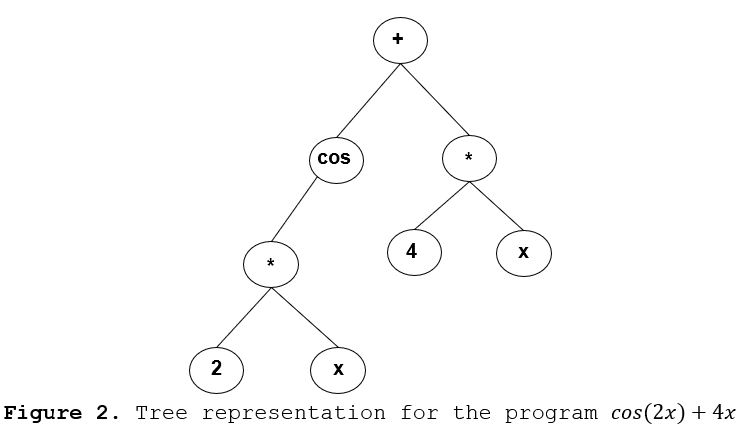
Genetic Programming
Historical GP and most current GP works handles functions or programs using parse trees to represent them. Trees are built from operators (trees’ nodes) and operands (terminals or trees’ leaves) chosen according to a domain problem. For classification problems, the goal is to find a function that outputs the correct labels of available data; For regression problems, the goal is to discover a mathematical expression that minimizes an error metric, a problem known as symbolic regression. In such a context, nodes are standard arithmetic operations and mathematical functions (e.g., sin, cos), and terminals are the problem variables and some ephemeral constants. Figure 2 illustrates a tree representation of the program cos(2x)+4x. In GP, the general fitness measure checks how well each program performs in a particular domain. The Mean Square Error (MSE) between the tree output and the desired value for all examples in the training set (aka fitness cases) is the basic fitness function for symbolic regression. In order to avoid the uncontroled growth of the tree size along evolution (aka bloat), the fitness function may combine MSE with parsimony such as size of the tree, or efficiency (e.g., computing budget). From a ML viewpoint, GP requires none or minor feature engineering. Likewise, it uses programs as representations to not require any prior knowledge, and it gets to a solution by evolving candidates in the chosen search space.
See relevant publications→
Human-guided learning
Although artificial intelligence technologies have a computational capacity far beyond humankind, intervention can sometimes be necessary. Without a human to guide the machine intelligence, the decisions it will make can not be fully reliable. The first step of guiding AI is to train it withwell prepared data. An ideal set of data should be compatible with the problem being solved, the particular goals of the business person and regulations. The decision on whether the data is suitable is made by humans. After using that data for training, the validation process shows how well the decisions can be made. At this point, if the hyperparameter tuning can not be automated, meaning that there are multiple criteria that need to be optimized, then human intervention and help is a must.
The concept of human-guided learning includes humans in the process and this helps machines to be trained more in agreement with the expectations of human experts in terms of factors such as ethics or bias or stability of the models. This collaboration is one of the key elements for building trust between humans and machines. Under changing real life scenarios, data keep changing and so do the models. For those cases, speed and efficiency of data and model validation become key factors that determine whether the machine learning model. TrustAI carries this mission of trust while building a set of solutions about Prognosis and Treatment Prediction for a very Rare Paraganglioma Cancer, Retail Willingness to Pay for Delivery at certain time intervals and Energy Forecast.
Check Publications →Counterfactual Analysis
Human-guided learning is based on using (human) cognitive processes to evaluate intermediate results and provide further guidance to the machine. Counterfactual analysis is one such process and TRUST-AI is making progress in this area. We formalized and quantified two relevant human heuristics in producing and evaluating causal explanations: the feasibility of a counterfactual explanation and its directed coherence. These terms, as well as different types of user constraints, were incorporated in a new algorithm for counterfactual search: CoDiCE.
See relevant publications →